There’s usually a tendency to select least-cost solutions incrementally, which typically means tweaking legacy estate rather than doing anything more transformative. While this does minimize delivery risk within individual projects, it can shift risk onto the institution’s future and allows it to cumulate until the “burning platform” moment requiring drastic, large-scale measures with no guarantee of success.
There needs to be a better way to weigh the pros and cons of solution options, balancing the short-term and the long term, the tactical and the strategic.
Technical Debt (TD) is a good framework to help determine relative merits of different solution options, if it is defined as the spend not accruing to the strategic target state of the assets being changed.
I like a geometric explanation:
 C is the Current State
C is the Current State
Solutions 1 & 2 have costs r1 and r2 and while 2 is cheaper (r2 < r1), they have radically different Tech Debt:
Minimizing Tech Debt simply means maximizing alignment of next state solution with long-term target state.
The reason why target state needs to be uncompromising is so that it can serve as a North Star to judge alignment against, or an etalon to weigh options by. Even if it’s not achievable for some years, it provides an important reference point.
This bit can be controversial, but it can be explained in terms of avoiding being locked into local maxima. When target state horizon is confined to the vicinity of the current state, one excludes significantly better but somewhat more distant possibilities:
What’s interesting is that typical corporate planning & funding horizons, which are rarely longer than a year, can be a very real limiting factor in being able to “see” far enough.
Tech Debt measures bases on the true, long-term target state, allow one to compensate for short-termism of planning horizons. It is therefore responsibility of architecture to not be bound by scope or timelines of individual projects, but look further ahead and provide a coherent, long-term vision that is aligned to technology strategy.
There needs to be a better way to weigh the pros and cons of solution options, balancing the short-term and the long term, the tactical and the strategic.
Technical Debt (TD) is a good framework to help determine relative merits of different solution options, if it is defined as the spend not accruing to the strategic target state of the assets being changed.
I like a geometric explanation:

T is the Target State – the true, uncompromising target one should aim for long-term – 3-5 year horizon
r is the funding available, circumscribing potential solution space – anything implementable has to lie within the circle of radius r around the current state
Solutions 1 & 2 have costs r1 and r2 and while 2 is cheaper (r2 < r1), they have radically different Tech Debt:
It’s clear that s2 (being the projection of r2 onto the line C-T) is actually negative, so solution 2 is a net detractor from T
Minimizing Tech Debt simply means maximizing alignment of next state solution with long-term target state.
The reason why target state needs to be uncompromising is so that it can serve as a North Star to judge alignment against, or an etalon to weigh options by. Even if it’s not achievable for some years, it provides an important reference point.
This bit can be controversial, but it can be explained in terms of avoiding being locked into local maxima. When target state horizon is confined to the vicinity of the current state, one excludes significantly better but somewhat more distant possibilities:
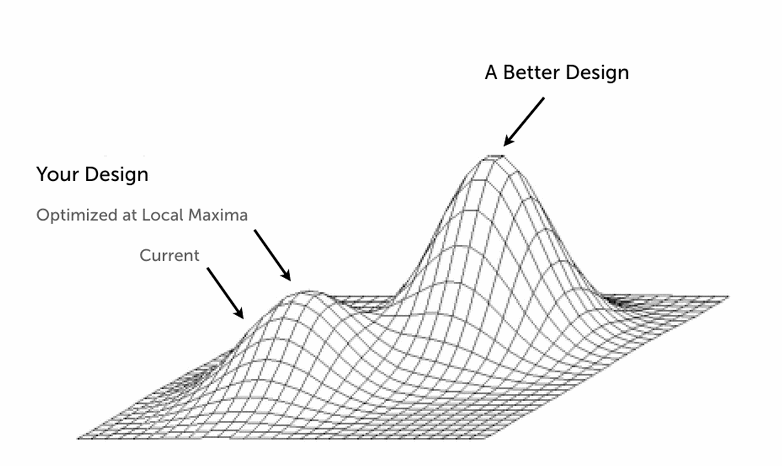 |
Local Maxima diagram by Joshua Porter
|
What’s interesting is that typical corporate planning & funding horizons, which are rarely longer than a year, can be a very real limiting factor in being able to “see” far enough.
Tech Debt measures bases on the true, long-term target state, allow one to compensate for short-termism of planning horizons. It is therefore responsibility of architecture to not be bound by scope or timelines of individual projects, but look further ahead and provide a coherent, long-term vision that is aligned to technology strategy.

.jpg/640px-Palace_Bridge_SPB_(img2).jpg)